6.2 Diagnostika a optimalizácia servera
V ideálnom svete by server IoT stačilo len nainštalovať podľa návodu a už nič viac neriešiť. Realita je však iná a je treba pripraviť sa na rôzne komplikácie.
Diagnostické nástroje
Niekedy sa stane, že niečo nám nefunguje. V takejto situácii je dobré poznať aspoň niektoré základné nástroje pre získanie informácií a diagnostiku. Začnime so získavaním informácií o operačnom systéme a počítači:
hostnamectl # komplexné informácie o OS, kerneli, základnej doske, BIOS verzii
uname -a # základné informácie o OSPrehľad o využití systémových prostriedkov:
df -h # voľné miesto na diskoch
free -h # využitie operačnej pamäte
btop # prehľadný monitoring CPU, pamäte, disku, siete a procesovPrehľad hardvéru:
lscpu # detailné informácie o CPU
lsusb # zoznam USB zariadení
lsblk # zoznam diskovPrehľad sieťových rozhraní a adries:
# {rozhranie} je napr. enp1s0
ip -brief address # stručný zoznam sieťových rozhraní a IP adries
ip -br a # to isté, ale skrátene
ip -brief link # stručný zoznam sieťových rozhraní a MAC adries
ip -br l # to isté, ale skrátene
networkctl status {rozhranie} # prehľadné komplexné informácie o rozhraní
ethtool {rozhranie} # podporované rýchlosti a funkcie + aktuálny stav a rýchlosťPoužité nástroje by mali byť súčasťou každej inštalácie Linuxu, s výnimkou btop, ktorý sme si nainštalovali v predošlej kapitole.
Všetky nasledujúce príkazy v tejto kapitole vykonávame s root právami. Pred začatím práce zadajte príkaz sudo -i.
Testovanie stability
Pokiaľ to so serverom myslíme vážne, základnou požiadavkou je jeho spoľahlivosť a stabilita. Tá môže byť ohrozená aj chybami hardvéru, najčastejšie chybnými pamäťovými modulmi, či nedostatočným chladením pri plnej záťaži. Preto je vhodné pred nasadením servera a pri každej zmene pamätí vykonať diagnostiku. Záťažové testy simulujú extrémne podmienky, ktoré môžu odhaliť skryté chyby napájania alebo chladenia ešte predtým, než serveru zveríte dôležité údaje.
Môžeme na to využiť testy stress-ng a memtester, dostupné cez APT:
apt install stress-ng memtesterUkážka konkrétnych testov:
# test CPU a cache (cca 10 minút):
stress-ng --class cpu-cache --cache-enable-all --seq 0 --verify --tz --verbose --timeout 10
# maximálne zahriatie CPU, sekvenčne a paralelne (cca 10 minút):
stress-ng --cpu 0 --cpu-method fft --vecwide 0 --vnni 0 --str 0 --wcs 0 --cpu 0 --verify --tz --seq 0 --timeout 100
stress-ng --cpu 0 --cpu-method fft --vecwide 0 --vnni 0 --str 0 --wcs 0 --verify --tz --timeout 600
# testy pamäte (cca 10 minút):
stress-ng --class memory --seq 1 --verify --verbose --timeout 10
stress-ng --vm 1 --vm-bytes 75% --verify --timeout 600
# cyklický dôkladný test pamäte:
memtester {veľkosť}G # treba zadať maximálne 90 % *voľnej* operačnej pamäteStav disku
Samostatným problémom je stav disku. Niekedy disk slúži len ako miesto pre uloženie súborov operačného systému, aby mohol naštartovať, no často je to aj miesto ukladania údajov, o ktoré by sme len neradi prišli bez varovania.
S.M.A.R.T.
Väčšina diskov podporuje monitoring stavu S.M.A.R.T. (Self-Monitoring, Analysis, and Reporting Technology), z ktorého vieme zistiť zaujímavé údaje, ako napríklad počet hodín prevádzky, počet štartov, počet chybných blokov, teplotu a podobne. Pre zistenie týchto zaujímavých údajov slúži program smartctl, ktorý je potrebné najskôr nainštalovať:
apt install smartmontoolsTipy pre OS Windows:
Balík smartmontools existuje aj pre Windows, nainštalovať ho možno podobne: winget install smartmontools
Ak má niekto radšej GUI, tak môže využiť CrystalDiskInfo: winget install CrystalDewWorld.CrystalDiskInfo
A následne už môžeme získavať informácie - v uvedených príkazoch je potrebné {disk} uviesť konkrétne, napríklad /dev/sda alebo /dev/nvme0n1 - zoznam diskov získame príkazom smartctl --scan:
smartctl --scan # zoznam diskov
smartctl -i {disk} # detailné informácie o modeli disku
smartctl -H {disk} # celkový stav (PASSED / FAILED)
smartctl -A {disk} # detailné informácie o stave diskuStavové parametre S.M.A.R.T.
Posledný uvedený príkaz vypíše mnoho informácií, z hľadiska bezpečnosti uložených údajov nás na SATA diskoch (HDD i SSD) zaujímajú predovšetkým tieto parametre (atribúty), ktoré by v ideálnom prípade mali byť na hodnote 0:
-
5 - Reallocated_Sector_Ct (počet premapovaných sektorov): Týka sa mechanického HDD (fyzické poškodenie platne), ale aj SSD (opotrebované bunky flash pamäte). Keď disk nájde fyzicky poškodené miesto, označí ho za zlé a nahradí ho „náhradným“ sektorom zo špeciálnej rezervnej oblasti. Ak toto číslo rastie, disk sa rozpadá. Ak je číslo stabilné, disk sa dá ešte používať, ale už mu netreba veriť.
-
197 (C5) - Current_Pending_Sector (čakajúce sektory): Sektory, ktoré disk nevedel prečítať a „čakajú na verdikt“. Akonáhle na ne disk úspešne zapíše dáta, zistí, či sú v poriadku alebo ich musí premapovať (presunúť do ID 5). Týka sa to mechanického HDD - pri SSD sa nečaká, rieši sa okamžite.
-
198 (C6) - Offline_Uncorrectable (neopraviteľné sektory): Sektory, ktoré disk nedokázal opraviť ani pomocou vlastných mechanizmov pri vnútornom teste. Sú nenávratne stratené.
-
199 (C7) - UDMA_CRC_Error_Count (chyby prenosu): Toto nehovorí o zdraví platní, ale o probléme s káblom alebo konektorom. Ak toto číslo nie je 0, pravdepodobne je zlý SATA kábel alebo zlý kontakt.
Pri S.M.A.R.T. údajoch si mám všímať aktuálny údaj (VALUE / Current) alebo „surovú hodnotu“ (RAW_VALUE)?
Väčšinou nás zaujíma surová hodnota (RAW_VALUE). Uvádza skutočný stav, napríklad prevádzkovú dobu v hodinách, teplotu v stupňoch Celzia, skutočný počet chybných blokov a podobne. Pozor však na disky Seagate - ak je hodnota niektorého parametra veľmi vysoká, je v jej bitoch zakódovaný nielen počet zlyhaní, ale aj počet úspešných operácií, teda toto číslo nám nič nepovie. Prípadne sú v tejto hodnote zakódované aj iné informácie a je len na softvéri, či ich vie dekódovať a zobraziť.
Aktuálna hodnota (VALUE) je v podstate „normalizovaná hodnota“, ktorá začína na vysokom čísle (typicky 100) a postupne sa znižuje, keď sa stav disku zhoršuje. Ak táto hodnota klesne až na prahovú hodnotu (THRESHOLD), disk oficiálne oznámi zlyhanie. To však už môže byť neskoro.
Ďalšie informácie sú skôr štatistické, ale môžu nás zaujímať:
- 9 - Power_On_Hours (počet hodín prevádzky): Pre mechanický HDD je to „tachometer“ - staré disky sú náchylnejšie na mechanickú únavu ložísk a motora. Pre SSD má nižšiu výpovednú hodnotu, no i elektronické súčiastky „starnú“.
- 12 (0C) - Power_Cycle_Count (počet zapnutí): Koľkokrát bol disk zapnutý/vypnutý. Pre mechanický disk je najväčší stres práve štart (roztočenie platní). Disk, ktorý beží 5 rokov v kuse, je na tom často lepšie ako ten, ktorý bol 5 rokov zapínaný 10-krát denne. V prípade SSD nie je tento údaj až tak podstatný, no príliš vysoké číslo môže poukazovať na problémy s napájaním.
-
194 (C2) - Temperature (teplota): Teplota mechanického HDD by nemala dlhodobo presahovať 45 - 50 °C. Každých 10 stupňov navyše drasticky skracuje životnosť ložísk a magnetickej vrstvy. V prípade SSD je kritická hranica cca 70 °C, pri prehrievaní disk začne spomaľovať.
Pri SSD nás môžu zaujímať aj údaje súvisiace s teoretickou životnosťou disku. Žiaľ, výrobcovia k nim nepristupujú jednotne, obvykle nájdeme len niektoré z uvedených informácií:
- 169 (A9) - Remaining_Lifetime_Perc alebo 202 Percent_Lifetime_Remain (zostávajúci život v percentách): Vyjadruje, koľko percent života ešte disku zostáva. Začína sa na hodnote 100 a postupne klesá. Keď dosiahne 0, disk prekonal životnosť deklarovanú výrobcom. Žiaľ, výrobcovia k tomuto údaju pristupujú rozdielne:
- Štýl „odpočítavanie“ (napr. Patriot, ADATA, Transcend, AMD / Silicon Motion): Atribút 169 priamo v poli RAW_VALUE ukazuje percentá, ktoré zostávajú.
- Štýl „opotrebovanie“ (napr. Crucial, Samsung): Atribút 202 funguje opačne - pole RAW_VALUE začína na 0 % a stúpa k 100 %. Program
smartctlto však prepočíta a v stĺpci VALUE zobrazí zostávajúcu životnosť.
- 167 (A7) Average_Erase_Count alebo 173 Ave_Block-Erase_Count (priemerný počet prepisov): Štatistický údaj, koľkokrát bola každá bunka v priemere prepisovaná. Podielom s hodnotou atribútu 168 môžeme vypočítať teoretickú opotrebovanosť buniek.
- 168 (A8) Max_Erase_Count_of_Spec (maximálny počet prepisov): Udáva, koľkokrát by podľa špecifikácií výrobcu mala každá bunka zvládnuť prepis. Pokiaľ tento údaj chýba, môžeme očakávať približne 1000 až 1500 cyklov pri lacných QLC / TLC flash pamätiach.
- 241 (F1) Host_Writes_32 MiB alebo 245 (F5) TLC_Writes_32 MiB (množstvo zapísaných údajov): Uvádza, koľko údajov sa na disk zapísalo, jednotkou je 32 MiB. Bežné SSD majú typickú životnosť (TBW) okolo 60 TiB.
- 246 (F6) Total_LBAs_Written (množstvo zapísaných sektorov): Podobne ako atribút 245, no jednotkou je sektor. Ten má obvykle veľkosť 512 B (to zistíme cez
smartctl -i)
Pri interpretácii SMART hodnôt je nutné sledovať nielen ID, ale aj názov a jednotky atribútu, pretože sa medzi výrobcami (a dokonca aj medzi modelmi rovnakého výrobcu) líšia. Zatiaľ čo jeden disk uvádza zápisy pod ID 246 v sektoroch, iný pod ID 241 alebo 245 v 32 MiB blokoch.
Praktická situácia - starý disk AMD (Silicon Motion) v serveri uvádza tieto údaje:
ID# ATTRIBUTE_NAME FLAG VALUE WORST THRESH TYPE UPDATED WHEN_FAILED RAW_VALUE 9 Power_On_Hours 0x0000 100 100 000 Old_age Offline - 12293 167 Average_Erase_Count 0x0000 100 100 000 Old_age Offline - 117 168 Max_Erase_Count_of_Spec 0x0000 100 100 000 Old_age Offline - 1000 169 Remaining_Lifetime_Perc 0x0000 100 100 000 Old_age Offline - 89 177 Wear_Leveling_Count 0x0000 100 100 050 Old_age Offline - 80 241 Host_Writes_32 MiB 0x0000 100 100 000 Old_age Offline - 491406 245 TLC_Writes_32 MiB 0x0000 100 100 000 Old_age Offline - 299060Z údajov je možné vyčítať, že:
- disk bežal zhruba 1 a pol roka (12293 hodín);
- v priemere sa každá bunka prepísala 117-krát z limitu 1000, čo predstavuje 11,7 % opotrebovanie;
- disku zostáva 89 % života;
- disk zapísal 15 TiB údajov, čo je cca 25 % životnosti.
Disk Crucial, ktorý slúžil v notebooku a teraz je v serveri, uvádza:
ID# ATTRIBUTE_NAME FLAG VALUE WORST THRESH TYPE UPDATED WHEN_FAILED RAW_VALUE 9 Power_On_Hours 0x0032 100 100 000 Old_age Always - 2915 173 Ave_Block-Erase_Count 0x0032 003 003 000 Old_age Always - 70 202 Percent_Lifetime_Remain 0x0030 097 097 001 Old_age Offline - 3 246 Total_LBAs_Written 0x0032 100 100 000 Old_age Always - 8525269776Z údajov je možné vyčítať, že:
- disk beží len zhruba 4 mesiace (2915 hodín);
- v priemere sa každá bunka prepísala 70-krát, no limit nepoznáme;
- disku zostáva 97 % života;
- disk zapísal 4 TiB údajov, čo je cca 7 % životnosti.
Testovanie S.M.A.R.T.
Na SATA diskoch (nie NVMe) môžeme spustiť aj S.M.A.R.T. testovanie - počas neho je možné disk používať, no bude spomalený a neodporúča sa to. Lepšie je testovať mimo prevádzky (napríklad v noci):
smartctl -t short {disk} # spustenie rýchleho testu (cca 2 až 5 minút)
smartctl -t long {disk} # spustenie dlhého testu (cca 1 noc)
smartctl -l selftest {disk} # protokol posledných testovNVMe disky
V prípade NVMe diskov diagnostika funguje odlišne (autodiagnostiku si robia priebežne počas prevádzky), ale základné testy sú často dostupné - v novších verziách NVMe 1.3+ je možné spustiť „short“ test aj manuálne. Zistené údaje nemajú číselné ID a sú trochu inak pomenované:
- Critical Warning: U NVMe diskov je toto najdôležitejšie pole. Na rozdiel od SATA diskov, kde musíme sledovať desiatky atribútov, NVMe zjednodušuje diagnostiku do tohto kritického indikátora. Ak je tam 0, všetko je OK. Akékoľvek iné číslo znamená prehrievanie alebo vážnu hardvérovú chybu.
- Available Spare: Je to ekvivalent k 5 - Reallocated_Sector_Ct, ale obrátene - určuje, koľko je ešte k dispozícii záložnej kapacity, teda 100 % je ideálny stav nového disku. SSD má vždy niečo „navyše“, čo nie je viditeľné pre používateľa. Keď nejaká pamäťová bunka umrie, disk ju nahradí bunkou z tejto zálohy.
- Media and Data Integrity Errors: Ak je tu niečo iné ako nula, disk má problém s pamäťovými čipmi a začína prichádzať o dáta.
- Percentage Used: SSD majú obmedzený počet zápisov. Toto číslo ide od 0 % (nový) do 100 % (opotrebovaný). Keď dosiahne 100 %, neznamená to, že hneď umrie, ale už prekročil záruku výrobcu na počet zápisov.
- Data Units Written: Udáva, koľko dát (logických jednotiek, zväčša 1000 sektorov po 512 B) disk už zapísal. Výrobcovia garantujú napríklad 600 TB pre 1 TB disk.
- Údaje Power Cycles, Power On Hours a Temperature majú rovnaký význam, ako pri SATA SSD (uvedené vyššie).
Súborový systém
V dnešnej dobe sú SSD disky už samozrejmosťou, ktorá výrazne zvyšuje rýchlosť spúšťania operačného systému i aplikácií, ale aj rýchlosť inštalácie. Či sa jedná o staršie SATA SSD disky, prechodné M.2 SATA disky alebo modernejšie NVMe disky, v každom prípade sa jedná o flash pamäť, ktorá má teoreticky obmedzený počet prepisov jednotlivých pamäťových buniek. Hoci pre moderné NVMe to z praktického hľadiska bežne nie je problém a skôr disk vyhodíme pre jeho nepostačujúcu kapacitu ako by sme ho „zodrali“, pri serveroch sa situácia môže značne líšiť.
Niektoré servery potrebujú disk len na to, aby mali z čoho spustiť operačný systém a zapisujú naň len veľmi zriedka - tam disk vydrží „takmer večne“. No sú servery, a to v prostredí IoT veľmi časté, ktoré na disk sústavne ukladajú nové údaje do databázy a nové udalosti do protokolov. Preto by sme mali disk čo najviac šetriť a pri inštalácii OS je vhodné zvážiť výber súborového systému. Súborový systém môžeme v nainštalovanom OS zistiť rôznymi spôsobmi, napríklad:
lsblk -fBtrfs
Pri inštalácii Linuxu je obvykle predvolený systém ext4, ktorý je síce rokmi overený a stabilný, ale bol navrhnutý ešte v ére magnetických pevných diskov. Pre moderné servery s flash pamäťami je lepšou voľbou Btrfs (B-tree filesystem) alebo F2FS. V inštalátore klasického Linuxu (pre PC) je možné určiť rozloženie diskových oddielov a ich súborový systém), a tak nám nič nebráni zvoliť systém Btrfs:
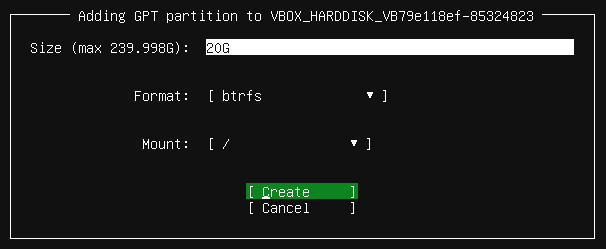
Súborový systém Btrfs má viaceré výhody, no pre nás sú podstatné hlavne tri:
- Pri prepise súboru novou verziou systém neprepisuje tie isté pamäťové bunky, ale zapíše novú verziu na iné voľné miesto - táto metóda sa nazýva Copy-on-Write (CoW). To zvyšuje bezpečnosť údajov (pri výpadku napájania neprídeme o pôvodný súbor) a umožňuje efektívne vytváranie snímok súborov (spomínané ďalej v texte). Zároveň to prispieva k rovnomernejšiemu opotrebovávaniu pamäťových buniek.
- Umožňuje zapnúť transparentnú kompresiu údajov, čo samozrejme aj ušetrí miesto (a to v prípade protokolov a iných textových súborov veľmi zásadne), ale môže dokonca aj zvýšiť rýchlosť čítania i zápisu (hlavne pri rýchlom CPU a pomalšom SSD), pretože nie je potrebné ukladať také množstvo údajov.
- Snímky (snapshots) umožňujú urobiť „fotku“ stavu celého disku pred nejakou väčšou zmenou a ak sa niečo pokazí, môžeme sa veľmi jednoducho vrátiť k predošlému stavu.
Pozor na databázy: Hoci je CoW skvelá vlastnosť pre stabilitu systému, pre súbory s častým náhodným zápisom (ako sú databázy) spôsobuje extrémnu fragmentáciu. Súbor sa rozkúskuje na tisíce častí, čo spomaľuje procesor a reakcie servera. V takých prípadoch je lepšie CoW pre konkrétny priečinok s databázou vypnúť, čo sa neskôr pri inštalácii konkrétnych služieb aj naučíme. O ochranu pamäťových buniek pred opotrebovaním sa pri moderných SSD diskoch postará ich vlastný riadiaci čip. V tomto prípade nie je potrebná ani ochrana pri náhlom výpadku, pretože moderné databázy používajú žurnál - najskôr si zapíšu zámer vykonať zmenu údajov a až následne ju vykoná, takže pri nečakanom výpadku sa vie zotaviť. Ochranu údajov teda preberá samotný databázový systém a súborový systém sa „stiahne do úzadia“, aby nebrzdil výkon.
Kompresia súborov
Samotné zvolenie súborového systému Btrfs však nezaistí kompresiu údajov. Tú je potrebné vyžiadať pridaním parametra „compress=zstd“ k pripájanému disku, a to úpravou súboru /etc/fstab:
nano /etc/fstabSú tam v samostatných riadkoch všetky pripájané diskové oddiely v tvare:
- {diskový oddiel} {bod pripojenia} {súborový systém} {parametre} {dve čísla}
Nás zaujímajú parametre - tie môžu byť viaceré (obvykle je ako prvý defaults), oddeľujú sa čiarkou (pozor, bez medzery!) a práve tam dopíšeme požadovaný parameter pre zapnutie kompresie. Situácia po zmene môže vyzerať napríklad takto:
/dev/disk/by-uuid/d1d29cff-26e6-402e-8802-b791b451e275 / btrfs defaults,compress=zstd 0 1Experti môžu ku kompresii zstd pridať za dvojbodku ešte stupeň kompresie (po 15, teda „zstd:15“) - predvolená je hodnota 3, čo je rozumný kompromis medzi efektivitou kompresie a záťažou CPU. V prípade veľmi rýchleho CPU by možno mohlo mať zmysel zvýšiť stupeň kompresie, no reálne to už neprinesie až taký rozdiel vo veľkosti údajov. A naopak, pre príliš starý a slabý CPU je možné zvoliť rýchlejší kompresný algoritmus lzo - ten samozrejme komprimuje menej. Ďalšie detaily nájdete v dokumentácii Btrfs - časť o kompresii.
Sú ešte nejaké zaujímavé parametre pre pripájanie disku?
Pri používaní Btrfs sa v prípade SSD oplatí pridať ešte parameter
discard=async(modernejší a rýchlejší spôsob spúšťania TRIM operácie) a pre magnetický HDD zaseautodefrag(vzhľadom na CoW dochádza ku fragmentácii súborov a to je pre HDD spomaľujúce, preto zapne automatickú defragmentáciu).V oboch prípadoch je pre server vhodný aj parameter
commit=60- ten spôsobí ukladanie metadát len raz za minútu (zoskupia sa a zapíšu naraz), čo tiež ušetrí zápisy. Mimochodom, pokiaľ tento parameter neuvedieme, Btrfs používa hodnotu 30 sekúnd (na rozdiel od ext4, kde je to len 5 sekúnd).Pre prídavné disky, ktoré nie sú nutné pre fungovanie operačného systému (sú na nich napríklad zálohy alebo zdieľané súbory), sa zvykne pridať ešte parameter
nofail- v prípade odpojenia disku nabehne OS aj bez neho.
Po pridaní parametra kompresie je potrebné ešte vykonať reštart a po novom nabehnutí OS sa ukladané údaje už budú komprimovať. A čo všetky tie staré, tie doteraz uložené? Tie zostanú, ako boli, no je možné ich skomprimovať aj dodatočne - čo môže trvať veľmi dlho, pokiaľ je na disku veľa údajov:
btrfs filesystem defragment -czstd -r /S tým, že symbol „/“ na konci je priečinok, ktorého súbory sa majú komprimovať, v tomto prípade ide o koreňový priečinok, teda komprimovať sa budú všetky pripojené disky a ich oddiely, ktoré sú v systéme Btrfs. Parameter -czstd hovorí, že sa má komprimovať algoritmom zstd.
Defragmentáciu na SSD spúšťame výnimočne len v tomto prípade, aby sme spätne skomprimovali staré údaje. Bežne ju na SSD nepoužívame.
Transparentná kompresia je skvelá vec, no určite nás bude zaujímať aj výsledok - koľko miesta na disku sme ušetrili. To je možné zistiť nástrojom compsize:
# nainštalujeme nástroj compsize
apt install compsize
# ak ho nenájde, môžeme skúsiť
apt install btrfs-compsize
# prípadne nájsť jeho presný názov cez
apt search compsize
# a teraz konečne zistíme štatistiku celého súborového systému (root priečinok /)
compsize -x /Zdržanie pri štarte servera
Súborový systém Btrfs prináša vcelku kuriózny problém: každý štart sa zdrží o 30 sekúnd. Nie je to vinou Btrfs, ale boot manažéra GRUB. Ten dokáže z Btrfs čítať údaje potrebné na štart, ale nedokáže naň zapisovať. Preto tomu nevie po úspešnom štarte zmazať príznak zlyhania, a tak pri každom ďalšom zapnutí „pre istotu“ čaká na zásah používateľa.
Toto zdržanie môžeme odstrániť pridaním inštrukcie GRUB_RECORDFAIL_TIMEOUT=0 do konfiguračného súboru /etc/default/grub a následnou aktualizáciou zavádzača:
echo "GRUB_RECORDFAIL_TIMEOUT=0" >> /etc/default/grub
update-grubViaceré sieťové rozhrania
Niekedy má server viaceré sieťové karty (napríklad integrovanú 1 Gb/s a prídavnú 2,5 Gb/s). Pokiaľ nie sú do siete pripojené obe, Linux môže pri štarte uviaznuť až na 2 minúty v stave networkd-wait-online, pretože sa snaží nakonfigurovať všetky dostupné rozhrania.
Riešenie je však jednoduché - v konfigurácii Netplanu (súbor /etc/netplan/*.yaml) označíme rozhrania ako voliteľné parametrom optional: true. Systém tak naštartuje okamžite a sieťovú adresu si na danej karte vypýta až vtedy, keď do nej reálne zapojíme kábel. Vyzerať to môže napríklad takto:
network:
version: 2
ethernets:
enp1s0:
dhcp4: true
dhcp6: true
optional: true
enp2s0:
dhcp4: true
dhcp6: true
optional: truePri zmenách sieťových nastavení je treba byť veľmi opatrný - obzvlášť v prípade konfigurácie „na diaľku“, čo je v praxi takmer vždy. Asi nik nechce po chybe zostať odpojený! A chyba sa spraví veľmi ľahko, v YAML stačí zle odsadiť… Preto je vhodné zmenené nastavenia otestovať príkazom netplan try - ten aplikuje nastavenia ihneď, no pokiaľ zmeny do 2 minút nepotvrdíme, vráti ich späť. Nepripomína nám to Safe Mode na zariadeniach MikroTik, ktorý nás neraz zachránil pri práci v kurze počítačových sietí? 😉
Môžeme všetky sieťové rozhrania označiť ako voliteľné?
V podstate áno. Je však situácia, kedy by to mohol byť problém: Ak by sme mali na serveri pripojené sieťové disky (NFS, Samba) cez /etc/fstab. Pokiaľ pri štarte nie je dostupná sieť, pokus o namontovanie týchto diskov pri štarte zlyhá. Otázne je, či by prípadné čakanie pomohlo - to už musí každý zvážiť v konkrétnej situácii.
Aktualizácia firmvéru
Kým softvér aktualizujeme cez APT, na aktualizáciu hardvéru (jeho firmvéru) slúži nástroj fwupd, ktorý je potrebné najskôr nainštalovať:
apt install fwupdTento nástroj je v praxi použiteľný najmä pre mini PC s architektúrou x86 od výrobcov ako Dell (modely Optiplex), Lenovo (ThinkCentre), HP (EliteDesk, ProDesk, Z-Workstation), či Intel (NUC). Ostatní výrobcovia túto formu, žiaľ, veľmi nepodporujú.
Poznámka: Na Raspberry Pi sa pre tento účel používa špecifický nástroj rpi-eeprom-update.
Tento nástroj dokáže priamo z terminálu aktualizovať firmvér, no vyžaduje, aby bol systém nainštalovaný v režime UEFI. Výrobcovia týmto spôsobom môžu posielať dôležité bezpečnostné záplaty nielen pre hlavný BIOS / UEFI základnej dosky, ale aj opravy pre SSD disky, sieťové karty, či TPM moduly. Pri IoT serveri, ktorý beží non-stop, chceme mať záplaty proti kritickým chybám, akými boli napríklad Spectre a Meltdown.
Použitie nástroja fwupd:
fwupdmgr refresh # stiahnutie informácií o nových verziách
fwupdmgr get-devices # zobrazenie informácií o zariadeniach
fwupdmgr get-updates # kontrola dostupných aktualizácií
fwupdmgr update # vykonanie aktualizáciePre vykonanie aktualizácie je po skončení procesu takmer vždy potrebný reštart systému. Či je to skutočne tak, zistíme prítomnosťou súboru /var/run/reboot-required.
Aktualizácia mikrokódu CPU
Okrem firmvéru existuje ešte jedna špecifická vrstva „opráv“ hardvéru - mikrokód procesora. Sú to drobné opravy chýb v logike procesora od výrobcov Intel alebo AMD. Hoci sa tieto opravy môžu dostať do počítača cez aktualizáciu BIOSu, výrobcovia základných dosiek ich často vydávajú so značným oneskorením.
Operačný systém Linux však dokáže tieto opravy aplikovať sám pri každom štarte (bootovaní). Je to najrýchlejšia cesta, ako zabezpečiť procesor proti známym zraniteľnostiam, aj keď výrobca PC už nevydáva nové verzie BIOSu. Slúžia na to nástroje intel-microcode a amd64-microcode, ktoré sú v Linuxe bežne predinštalované a každá aktualizácia systému nainštaluje aj prípadné opravy mikrokódu.
Či je systém a procesor aktuálne v bezpečí a či má aplikované všetky dôležité záplaty, je možné kedykoľvek overiť nahliadnutím do systémových súborov:
tail /sys/devices/system/cpu/vulnerabilities/*Tento príkaz vypíše zoznam známych hrozieb a pri každej z nich uvedie stav (napríklad Not affected alebo Mitigation). Ak je pri niektorej položke uvedené Vulnerable, znamená to, že počítaču chýba aktualizácia BIOSu alebo mikrokódu.
Prípadne si môžeme zobraziť len zraniteľnosti, možné varianty príkazu:
grep -r "Vulnerable" /sys/devices/system/cpu/vulnerabilities/
lscpu | grep "Vulnerable"Žiaľ, nie vždy je dostupná oprava (hlavne pre staršie CPU), no v domácom prostredí IoT servera v LAN to zvyčajne nepredstavuje kritické bezpečnostné riziko.
Zvuková signalizácia
Určite to nie je potrebné, ale môže byť zaujímavé náš server obohatiť o zvukové signály, pokiaľ na základnej doske máme bzučiak (buzzer, speaker). Ubuntu ho má štandardne úplne vypnutý, no server nie je desktop a nám môže poslúžiť.
ugly and loud noise, getting on everyone's nerves; this should be done by a nice pulseaudio bing
(komentár k zariadeniu pcspkr v Ubuntu Server)
Aby sme mohli vôbec bzučiak používať, v súbore /etc/modprobe.d/blacklist.conf je potrebné zakomentovať riadok so zákazom zariadenia pcspkr:
sed -i "s/blacklist pcspkr/#blacklist pcspkr/" /etc/modprobe.d/blacklist.conf
# a aby začal fungovať hneď, nie až po reštarte:
modprobe pcspkrPípnutie pri štarte
Boot manažér GRUB umožňuje pípnuť pri svojom spustení, teda v okamihu, keď BIOS odovzdá riadenie operačnému systému. V súbore /etc/default/grub je potrebné povoliť konzolový formát parametrom GRUB_TERMINAL=console a pridať samotný zvuk parametrom GRUB_INIT_TUNE="údaje", kde údaje sú postupnosť: tempo frekvencia_1 trvanie_1 frekvencia_2 trvanie_2 … Trvanie nemá konkrétnu jednotku, ale súvisí s tempom: (60 / tempo) je trvanie hodnoty 1. Pre jednoduchosť je vhodná hodnota 600, vtedy 1 trvanie znamená 0,1 s.
Príklad aktivácie dvojitého pípnutia (získanie mince v hre Super Mario):
sed -i "s/#GRUB_TERMINAL=console/GRUB_TERMINAL=console/" /etc/default/grub
sed -i 's/#GRUB_INIT_TUNE=.*/GRUB_INIT_TUNE="600 988 1 1318 4"/' /etc/default/grub
update-grubMelódie pri udalosti
Aby sme mohli pohodlne generovať tóny kedykoľvek (zväčša v skriptoch pri nejakej udalosti), oplatí sa nainštalovať si beep a nášmu používateľskému účtu prideliť právo používať bzučiak:
apt install beep
# ak má byť beep funkčný aj pre používateľa, nielen pre systém:
usermod -aG input $(logname)
#prejaví sa až po odhlásení a opätovnom prihlásení používateľaCelkom praktické by bolo zahratie zvučky, keď štartovanie OS skončí a systém je pripravený - teda po nabehnutí všetkých služieb. Dá sa to dosiahnuť jednoducho vytvorením vlastnej služby. Najskôr v priečinku /etc/systemd/system vytvoríme službu, napríklad s názvom boot-beep:
nano /etc/systemd/system/boot-beep.serviceDo tohoto súboru vložíme jej popis:
[Unit]
Description=pípnutie po úspešnom štarte
After=multi-user.target
[Service]
Type=oneshot
ExecStart=/usr/bin/beep -f 440 -l 50 -n -f 554 -l 50 -n -f 659 -l 50 -n -f 880 -l 150
RemainAfterExit=yes
[Install]
WantedBy=multi-user.targetA následne službu zaktivujeme:
systemctl enable boot-beep.service